Emotion Recognition from Audio
Feb 2025 – May 2025
Emotions shape how we communicate — but can a machine learn to hear them? This project explores that question by training CNN models to recognize emotions directly from audio, without ever reading a word.
The key idea: convert raw audio into spectrograms — visual "heat maps" that reveal how the frequencies of a sound change over time. Instead of processing waveforms, the model looks at these images and learns to distinguish patterns tied to emotions like anger, calm, happiness, or sadness. Audio clips were sourced from the RAVDESS dataset, covering both song and speech.
One early insight was that song and speech carry emotion very differently, so we trained two separate models. The song model reached 77.60% validation accuracy, performing best on neutral, angry, calm, and happy. The speech model reached 62.77%, best on disgust, calm, and angry — speech emotion proved harder to generalize.
To make the models more robust, we applied data augmentation: adding background noise, shifting pitch, and modifying playback speed to expand the training set and reduce overfitting.
As a fun real-world test, we ran the model on a spectrogram generated from a real lecture recording — a professor saying "please fill out course evaluation when you get back to your dorm." The model's prediction: calm, with 95% confidence.
The trained model is also deployed as an interactive demo on Hugging Face Spaces — upload your own audio clip and see what the model hears.
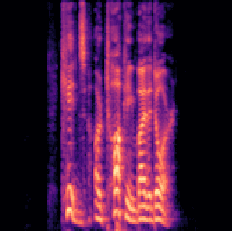
Speech spectrogram — angry emotion. Brighter regions indicate higher energy frequencies, characteristic of the sharp, high-intensity vocal patterns of anger.